

Spring-Cloud-Data-Flow(SCDF)란?
Spring Cloud Data Flow 는 Cloud Foundry 및 Kubernetes에서 스트리밍 및 일괄 데이터 처리 파이프라인을 구축하기 위한 마이크로서비스 기반 툴킷
SCDF 특징
- 웹 대시보드, REST API, JAVA DSL, console shell 다양한 인터페이스로 제공
- 로컬, Cloud Foundry 및 Kubernetes 위에서 설치 및 운영 가능
- 스케줄링 기능은 Cloud Foundry 및 Kubernetes에서만 사용 가능, 일반 서버에서는 X
- SCDF의 상태 및 데이터 관리는 관계형 DB에서 관리
- 기본적으로 h2 DB와 연동되지만 실행시 데이터가 초기화 되기 때문에 운영에서 사용시 MySQL, MariaDB와 같은 관계형 DB를 연결해주어야 함
- 지원되는 데이터베이스는 H2, HSQLDB, MySQL, Oracle, Postgresql, DB2 및 SqlServer가 있음
목표
⭐️ spring batch 모니터링을 위한 SCDF 구축⭐️
배치를 운영하게 되면 모니터링 시스템이 필수불가결하다.
Jenkins가 스케줄링 실행 및 실행 결과 여부, 로그 모니터링 등 다양한 기능을 제공해주기 때문에 보편적으로 많이 사용되는 것 같다.
그런데 만약 Jenkins에서 스케줄링으로 실행하는 배치가 아니라면?
데몬 형태로 계속 띄어져 있고 어떠한 이벤트가 발생했을 때 실행되는 이벤트성 배치라면? Jenkins로 실행 결과를 모니터링하기가 조금 애매해진다. (찾아보면 방법이 있을수도 있지만)
원래 spring에서는 spring batch로 구현한 어플리케이션의 모니터링 및 관리를 위해 spring batch admin을 별도 서비스했었다고 한다.
하지만 deprecated되어 2017년 12월 31일부로 서비스를 종료했다. 그 후 spring에서는 spring batch admin의 대체제로 SCDF 사용을 공식적으로 권고하고 있다.
그래서 이번에는 spring batch로 구현한 이벤트 배치일 때 모니터링 솔루션으로 사용하기 위한 SCDF를 구축해보고자 한다.
SCDF 설치
1. 설치 환경
SCDF는 local, cloud foundry, kubernetes 이렇게 3가지 환경에 설치할 수 있다.
단 local에서는 스케줄링 기능은 사용할 수 없다. 어차피 사용하지 않을 기능이라 간단하게 local에 설치하겠다.

2. 설치 방법
설치 방법은 크게 2가지가 있다. 이번에는 jar파일로 설치해보겠다.
1) docker로 설치하기
2) jar 파일로 설치하기
curl 명령어로 jar파일을 다운로드한다. 공식 홈페이지에서 2.8.1버전으로 예시를 주고 있어 나도 해당 버전을 설치했다.
curl -k -L --output spring-cloud-dataflow-server-2.8.1.jar https://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-server/2.8.1/spring-cloud-dataflow-server-2.8.1.jar
일단 아무 설정 없이 설치한 jar 파일만 실행해보자.
java -jar spring-cloud-dataflow-server-2.8.1.jar
터미널에 아래와 같은 로그가 출력되면 정상적으로 SCDF가 뜬것이다.
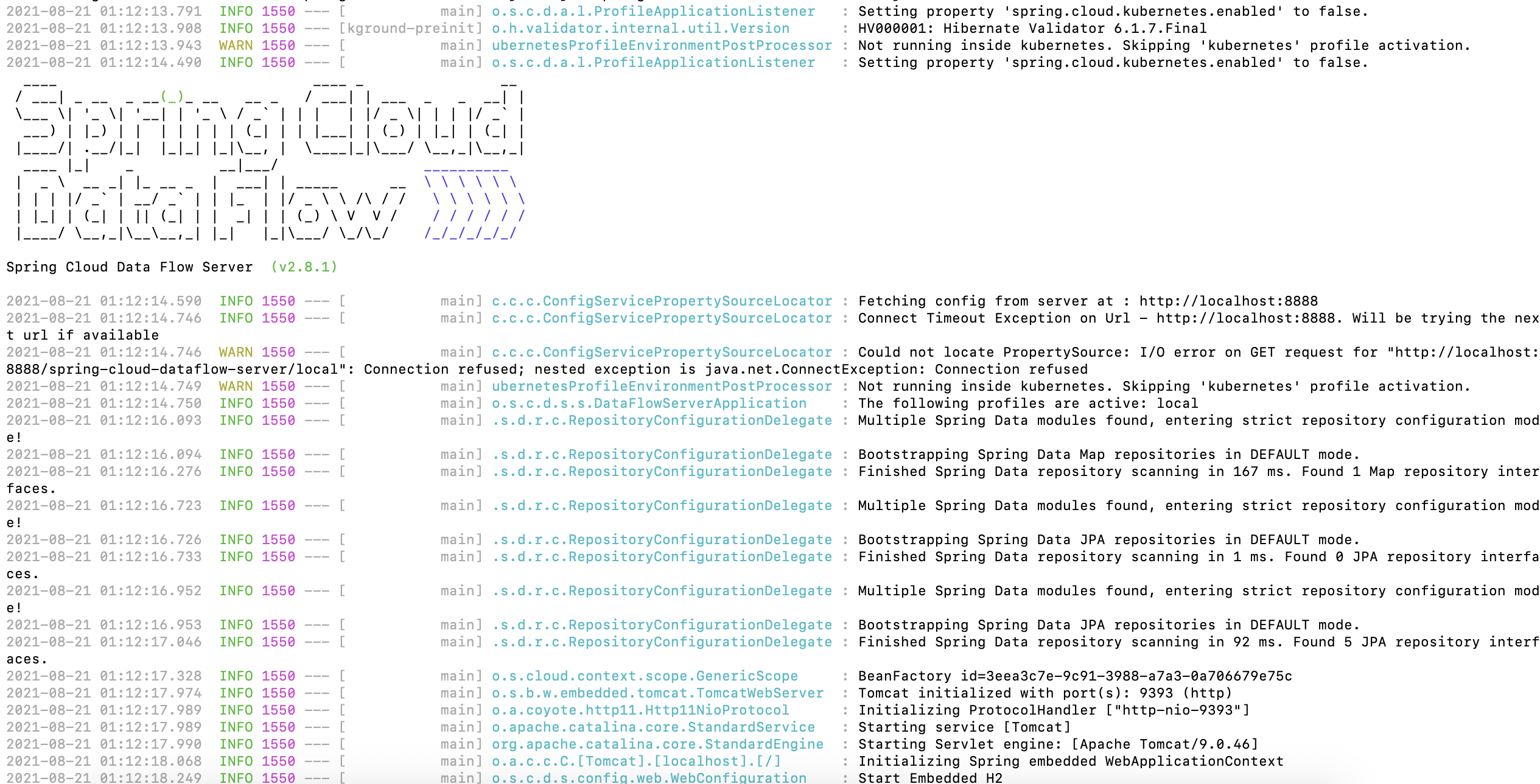
브라우저에서 http://localhost:9393/dashboard로 접속해본다. SCDF의 기본 포트는 9393이다.
아래와 같은 UI가 등장하면 성공이다.
SCDF로 Spring Batch 모니터링하기
그럼 이제 본격적으로 SCDF로 spring batch를 모니터링하는 프로젝트를 만들어 보자.
먼저 Spring Cloud Task 기반의 spring batch 프로젝트가 있어야 한다. 지금은 spring batch 프로젝트 만들기가 주 목적이 아니기 때문에 spring cloud data flow 공식 홈페이지에서 제공하는 데모 프로젝트를 사용하려고 한다.
DB 및 테이블 생성하기
SCDF에서 spring batch 실행 정보를 제공하는 프로세스는 다음과 같다.
1. spring batch를 SCDF에서 모니터링할 수 있는 Spring Cloud Task로 task화 시킨다.
- spring batch 프로젝트에 @EnableTask 어노테이션을 붙이면 됨.
2. spring batch기반의 배치를 실행한다. 그러면 연결한 DB의 spring batch 메타테이블들, spring cloud task 메타테이블들에 실행 결과가 기록된다.
3. SCDF에서 spring batch, spring cloud task 메타 테이블에서 정보를 가져와 사용자에게 예쁘게 세팅하여 제공한다.

그럼 DB에 Spring batch와 SCDF가 공유하는 메타 테이블을 먼저 생성하여 보자
나는 docker를 이용하여 MySQL을 설치하고 task라는 이름의 database까지 생성해놓았다.
database이름을 task라고 지정한 이유는 위 데모 프로젝트에서 그렇게 하라고 했기 때문이다.
docker compose 실행파일은 github에 올려놓겠다.
database가 생성되었으면 그 안에 spring batch, spring cloud task 메타테이블들을 생성한다.
spring batch 메타 테이블들은 다음과 같다.
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME NOT NULL,
START_TIME DATETIME DEFAULT NULL ,
END_TIME DATETIME DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME,
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME NOT NULL ,
END_TIME DATETIME DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME,
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);
Spring Cloud Task의 메타 테이블들은 다음과 같다.
/* hibernate_sequence */
create table if not exists hibernate_sequence (
next_val bigint
);
insert into hibernate_sequence (next_val)
select * from (select 1 as next_val) as temp
where not exists(select * from hibernate_sequence);
/* app_registration */
create table app_registration (
id bigint not null,
object_version bigint,
default_version bit,
metadata_uri longtext,
name varchar(255),
type integer,
uri longtext,
version varchar(255),
primary key (id)
);
/* task_deployment */
create table task_deployment (
id bigint not null,
object_version bigint,
task_deployment_id varchar(255) not null,
task_definition_name varchar(255) not null,
platform_name varchar(255) not null,
created_on datetime,
primary key (id)
);
/* audit_records */
create table audit_records (
id bigint not null,
audit_action bigint,
audit_data longtext,
audit_operation bigint,
correlation_id varchar(255),
created_by varchar(255),
created_on datetime,
primary key (id)
);
alter table audit_records add platform_name varchar(255);
/* task_definitions */
create table task_definitions (
definition_name varchar(255) not null,
definition longtext,
primary key (definition_name)
);
alter table task_definitions add description varchar(255);
/* task info tables */
CREATE TABLE TASK_EXECUTION (
TASK_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
START_TIME DATETIME DEFAULT NULL,
END_TIME DATETIME DEFAULT NULL,
TASK_NAME VARCHAR(100),
EXIT_CODE INTEGER,
EXIT_MESSAGE VARCHAR(2500),
ERROR_MESSAGE VARCHAR(2500),
LAST_UPDATED TIMESTAMP,
EXTERNAL_EXECUTION_ID VARCHAR(255),
PARENT_EXECUTION_ID BIGINT
);
CREATE TABLE TASK_EXECUTION_PARAMS (
TASK_EXECUTION_ID BIGINT NOT NULL,
TASK_PARAM VARCHAR(2500),
constraint TASK_EXEC_PARAMS_FK foreign key (TASK_EXECUTION_ID)
references TASK_EXECUTION(TASK_EXECUTION_ID)
);
CREATE TABLE TASK_TASK_BATCH (
TASK_EXECUTION_ID BIGINT NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
constraint TASK_EXEC_BATCH_FK foreign key (TASK_EXECUTION_ID)
references TASK_EXECUTION(TASK_EXECUTION_ID)
);
CREATE TABLE TASK_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
);
INSERT INTO TASK_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp;
CREATE TABLE TASK_LOCK (
LOCK_KEY CHAR(36) NOT NULL,
REGION VARCHAR(100) NOT NULL,
CLIENT_ID CHAR(36),
CREATED_DATE DATETIME(6) NOT NULL,
constraint LOCK_PK primary key (LOCK_KEY, REGION)
);
/* task_execution_metadata */
CREATE TABLE task_execution_metadata (
id BIGINT NOT NULL,
task_execution_id BIGINT NOT NULL,
task_execution_manifest LONGTEXT,
primary key (id),
CONSTRAINT TASK_METADATA_FK FOREIGN KEY (task_execution_id)
REFERENCES TASK_EXECUTION(TASK_EXECUTION_ID)
);
CREATE TABLE task_execution_metadata_seq (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
);
INSERT INTO task_execution_metadata_seq (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from task_execution_metadata_seq);
Spring Batch 프로젝트 실행하여 배치 돌리기
아래 링크 클릭하여 batchsameples.zip 파일을 다운로드 받고 적당한 폴더로 옮겨 압축을 푼다.
그럼 이제 데모 프로젝트를 실제로 실행시켜 배치를 돌려보자.
휴대전화 데이터 제공업체가 고객을 위한 청구서를 작성한다고 가정하는 배치이다.
즉, 청구서를 작성하여 테이블에 그 내용을 insert시키는데 해당 테이블명은 BILL_STATEMENTS가 된다.

그 다음은 위 데모 프로젝트의 jar파일을 만들 것이다.
다운로드 받은 batchsample.zip의 압축을 풀면 다음과 같은 폴더 및 파일들이 있을 것이다.
해당 위치에서 아래 명령어를 실행한다.
./mvnw clean package
그럼 프로젝트 빌드가 시작되고 billrun 폴더 아래에 target 폴더가 만들어 질 것이다.target 폴더 안에는 해당 프로젝트의 jar파일이 들어가 있다.

jar파일까지 만들어졌으니 jar -jar 명령어로 배치를 실행시키면 된다.
java -jar {path}/billrun-0.0.1-SNAPSHOT.jar \
--spring.datasource.url=jdbc:mysql://localhost:3306/task \
--spring.datasource.username={username} \
--spring.datasource.password={password} \
--spring.datasource.driverClassName=com.mysql.jdbc.Driver \
--spring.datasource.initialization-mode=always \ // bill_statement 테이블을 초기화
아래와 같은 로그가 쭉 뜨면 성공

bill_statement에는 청구 결과 내용이 잘 insert되어 있다.
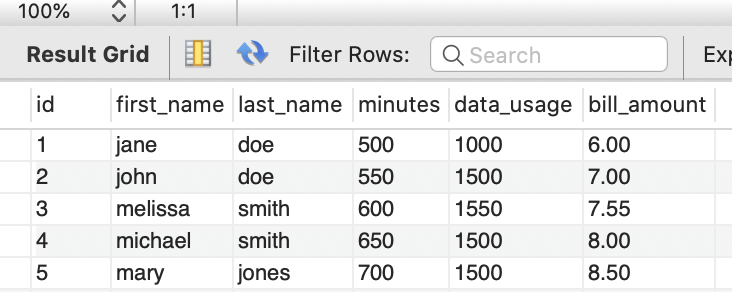
spring batch 아무 메타테이블에나 접속해보면 마찬가지로 실행 정보가 잘 들어가 있다. 아래 테이블은 task_execution 이다.

SCDF 실행하기
이제 마지막으로 SCDF만 실행하여 spring batch결과를 모니터링 하면 된다.
아래 명령어를 실행하여 SCDF를 실행한다.
java -jar spring-cloud-dataflow-server-2.8.1.jar \
--spring.datasource.url=jdbc:mysql://localhost:3306/task \ //연동하는 DB
--spring.datasource.username=batch_user \ // DB 계정
--spring.datasource.password=batch_user \ // DB 패스워드
--spring.datasource.driver-class-name=org.mariadb.jdbc.Driver \
--spring.cloud.dataflow.features.streams-enabled=false \ //대기열큐 활성화 여부, 배치잡 모니터링 시에는 필요없음
--spring.flyway.enabled=false // 실행할때마다 메타테이블 매번 생성 여부
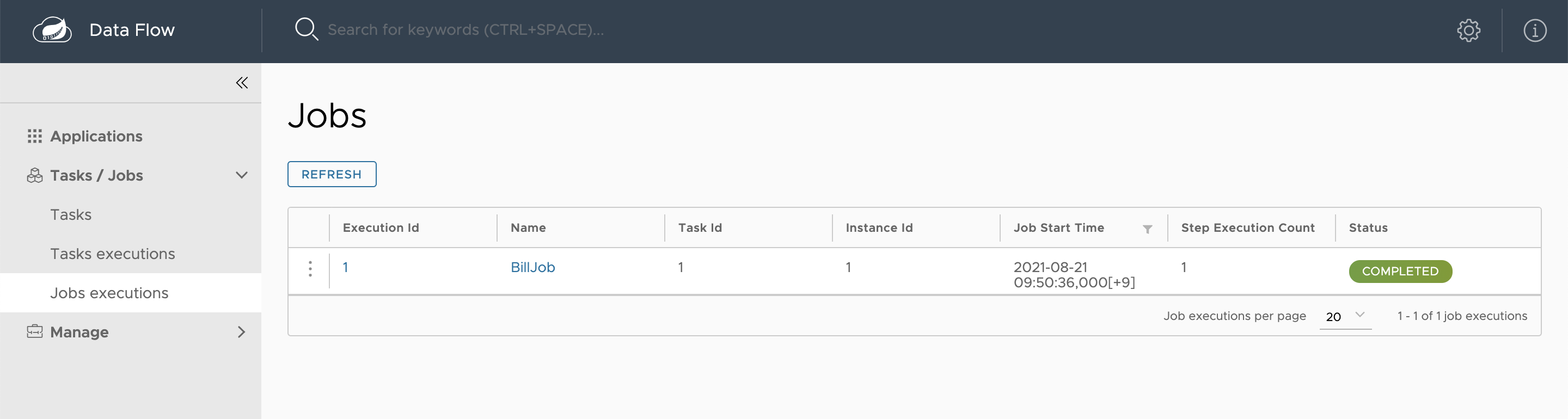
http://localhost:9393/dashboard/#/tasks-jobs/job-executions 을 접속하면 다음과 같이 BillJob이라는 배치가 실행된 결과를 대시보드 형태로 확인할 수 있다.
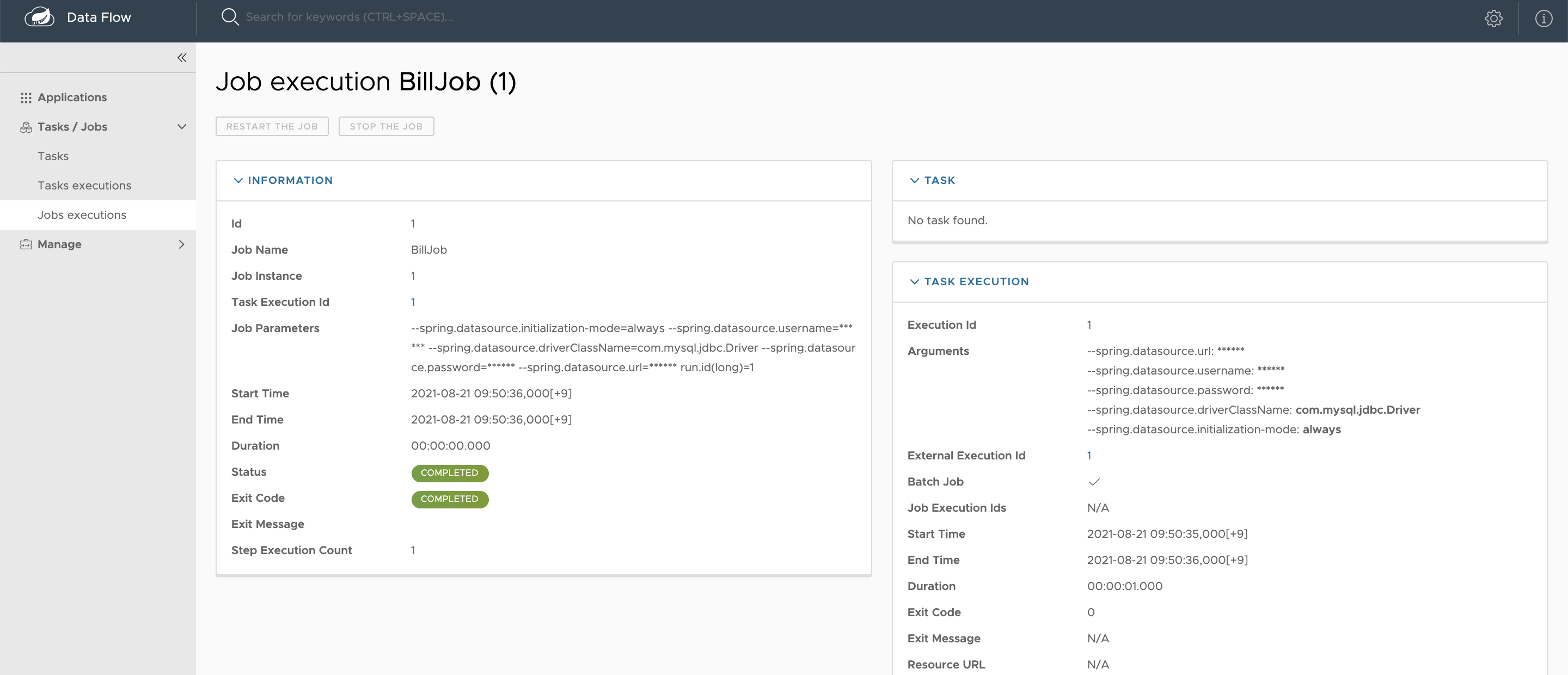
상세 화면
결론
간단하게 spring batch 실행 정보를 모니터링 하는 테스트만 해봤지만 spring cloud data flow는 이외에 다양하게 활용할 수 있다.
하지만 구글링으로 설명만 읽고는 사실 감이 잘 오지는 않는다.
spring batch 실행 정보를 UI로 확인할 수 있는 점은 꽤 유용한 서비스라고 생각한다.
spring batch로 프로젝트를 구현하면 메타 테이블 생성이 필수인데 사실 처음에는 이게 왜 존재해야하는 지 좀 짜증이 나기도 했다.
메타테이블의 의존성 때문에 spring batch로 배치를 개발할때 꽤 삽질을 많이 하기 때문이다.
하지만 메타테이블의 정보를 활용하여 실행 정보(실행 성공 여부, read, write횟수, 실행 시간 등)을 모니터링할 수 있게 해주는 SCDF를 발견하고는 존재의 이유를 약간 납득했다. 메타 테이블의 정보를 활용해야한다면 SCDF를 도입하는 것은 꽤 괜챃을 것 같다.
코드는 github에 올려놓았다.
참고
https://dataflow.spring.io/docs/installation/
https://spring.io/projects/spring-cloud-dataflow#overview
'개발 > Spring' 카테고리의 다른 글
| Spring Boot 배포 WAR 에서 JAR 로 변경하기 (Spring Boot Embedded Tomcat 사용하기) (2) | 2022.04.13 |
|---|---|
| QueryDSL + multi data source 연동하기 (0) | 2021.09.13 |
| webflux + reactive redis cache 적용하기 (2) | 2021.08.23 |